
Wir haben unseren ursprünglichen Blogbeitrag mit dem Release von Version 3.0.0 am 22.07.2026 aktualisiert.
Am 22. Juli 2026 hat das Projekt Paperless-ngx 3.0 veröffentlicht – nach gut zweieinhalb Monaten Beta-Phase ist v3.0.0 jetzt das offizielle Stable-Release. Es ist ein großer Sprung: Die Suche bekommt ein neues Backend, Dokumente können erstmals Versionen haben, das System für Arbeitsabläufe wird flexibler – und unter der Haube fliegen ein paar alte Zöpfe raus. Wir ordnen ein, was relevant ist und ob du direkt updaten solltest. Alle Aussagen basieren auf den offiziellen Release-Notes auf GitHub und unseren eigenen Tests.
Das Wichtigste in Kürze
- Stable seit 22. Juli 2026: Nach zwei Beta-Versionen seit Mai ist
v3.0.0das offizielle Release – das Docker-Tag:latestzeigt bereits darauf. - Tantivy ersetzt Whoosh: Die Volltextsuche ist deutlich schneller, durchsucht jetzt benutzerdefinierte Felder und Notizen – und ignoriert Akzente sowie Wortreihenfolge.
- Paperless AI (optional): Erstmals eine eingebaute LLM-Anbindung mit Vorschlägen für Titel, Tags und Korrespondent und einem Dokument-Chat – wahlweise über die OpenAI-API oder lokal per Ollama.
- Document File Versions: Mehrere Versionen eines Dokuments lassen sich als Einheit verwalten, statt sie als Duplikate anzulegen.
- Sharelink Bundles: Mehrere Dokumente lassen sich als ein Paket teilen, statt für jedes einen eigenen Sharelink zu erzeugen.
- Breaking Changes betreffen vor allem Self-Hoster: Python 3.10 und API v1 fallen weg, das
OCR_MODE=skip-Verhalten ändert sich und einigeCONSUMER_*-Variablen wurden umbenannt.
In unserem Paperles-ngx 3.0 Upgrade Guide erklären wir Schritt für Schritt, wie du updaten kannst.
Von der Beta zum Stable
Die 3.0 hat einen ordentlichen Beta-Zyklus hinter sich: Die erste Beta (v3.0.0-beta.rc1) erschien am 5. Mai 2026, Mitte Juli folgte eine zweite Runde mit Community-Feedback, Sicherheits-Fixes und Detailverbesserungen. Seit dem 22. Juli 2026 ist v3.0.0 das offizielle Stable-Release.
Das hat eine praktische Konsequenz: Die offiziellen Docker-Tags wie :latest zeigen jetzt auf die 3.0. Wer sein Setup auf latest betreibt und „mal eben“ aktualisiert, bekommt das Major-Upgrade automatisch – inklusive aller Breaking Changes weiter unten. Vor dem Update gehört deshalb ein vollständiges Backup inklusive Datenbank, media/ und data/ angelegt. Wie sich der Backup-Aufwand beim Self-Hosting zusammensetzt, haben wir im Artikel Paperless-ngx Self-Hosted vs. Managed Hosting beschrieben.
Tantivy: Suche, die endlich Spaß macht
Bisher basierte die Volltextsuche auf der in Python entwickelten Search Engine Whoosh – funktional, aber bei größeren Archiven spürbar langsam. Mit der 3.0 wechselt das Projekt auf die modernere und schnellere Tantivy Search-Engine, implementiert in Rust. Im Pull Request #12471 berichten die Entwickler:innen: Whoosh brauchte beim Profiling über 1,5 Minuten (gedeckelt bei 9.000 Queries), Tantivy etwa 30 Sekunden. Der eigentliche Gewinn zeigt sich aber beim Suchen selbst:
- Benutzerdefinierte Felder werden durchsuchbar. Mit
custom_fields.value:<term>suchst du gezielt in selbst angelegten Feldern, etwa nach einer Vertragsnummer. - Notizen sind indexiert.
notes.note:<term>findet Inhalte aus Dokumentnotizen,notes.user:<username>filtert nach Autor:in. - Diakritika werden ignoriert. „café“ findet auch „cafe“, „Müller“ auch „Mueller“.
- Wortreihenfolge ist egal. „rechnung huber 2026“ liefert dieselben Treffer wie „2026 huber rechnung“.
Wichtig beim Upgrade: Docker-Setups reindexieren automatisch beim ersten Start; Bare-Metal-Setups müssen document_index reindex einmalig ausführen.
Paperless AI: KI-Vorschläge und Dokument-Chat
Das auffälligste neue Feature ist Paperless AI (PR #10319) – erstmals eine eingebaute LLM-Anbindung im Core, statt über Community-Projekte. Sie ist optional und standardmäßig deaktiviert und kann zwei Dinge: Ergänzend zum eingebauten Klassifizierer (siehe Auto-Matching) schlägt ein Sprachmodell Titel, Tags und Korrespondent vor. Und du kannst Dokumente per Dokument-Chat befragen („Welche Kündigungsfrist steht in diesem Vertrag?“); optional baut Paperless dafür einen Vektorindex (RAG) über dein Archiv auf.
Entscheidend ist, welches Modell läuft. Über PAPERLESS_AI_LLM_BACKEND wählst du zwischen einer OpenAI-kompatiblen API und einem Ollama-Server.
Wichtig aus Datenschutz-Sicht: Du kannst eine beliebige OpenAI-kompatible API nutzen. Bei der Nutzung der offiziellen OpenAI-API verlassen deine Dokumenteninhalte den eigenen Server und gehen an den US-Anbieter – bei Rechnungen, Verträgen und Personalakten selten gewollt. Mit Ollama bleibt alles lokal – für DSGVO-relevante Archive ist das der „way to go“.
Neben Ollama können erfahrene Nutzer:innen sich alternativ mit Tools wie vLLM auch beliebige „open-weights“ Modelle lokal mit OpenAI-kompatibler Schnittstelle aufsetzen. In beiden Fällen wird jedoch eine (typischerweise nicht ganz preisgünstige) Grafikkarte mit ausreichend VRAM benötigt. Wer stattdessen einen externen, aber DSGVO-konformen und EU-basierten Inference Provider verwenden will, ist mit den Angeboten von Scaleway (Generate APIs) oder IONOS (AI Model Hub) gut beraten.
Remote OCR via Azure
Verwandt, aber denn verschieden: Mit Remote OCR (PR #10320) lässt sich die Texterkennung an Azure AI Document Intelligence auslagern, statt lokal mit OCRmyPDF und Tesseract zu arbeiten. Das kann bei schwierigen Scans bessere Ergebnisse liefern, schickt die Dokumente aber ebenfalls in die Cloud – optional, das lokale OCR bleibt Standard.
Document File Versions: Versionen ohne Duplikate
Bisher landete eine neu gescannte Rechnung als zweites Dokument im Archiv – Tags doppelt pflegen, alte Version löschen, Verweise prüfen. Mit PR #12061 führt Paperless-ngx Document File Versions ein: Jedes Dokument kann mehrere Versionen haben, die als Einheit verwaltet werden. Vorschaubilder, Sharelinks und Suchergebnisse zeigen automatisch auf das „Root“-Dokument, sodass keine Verweise brechen. Das Audit-Log erfasst, wann welche Version angelegt wurde – relevant für GoBD-Setups (siehe Paperless-ngx GoBD-konform nutzen).
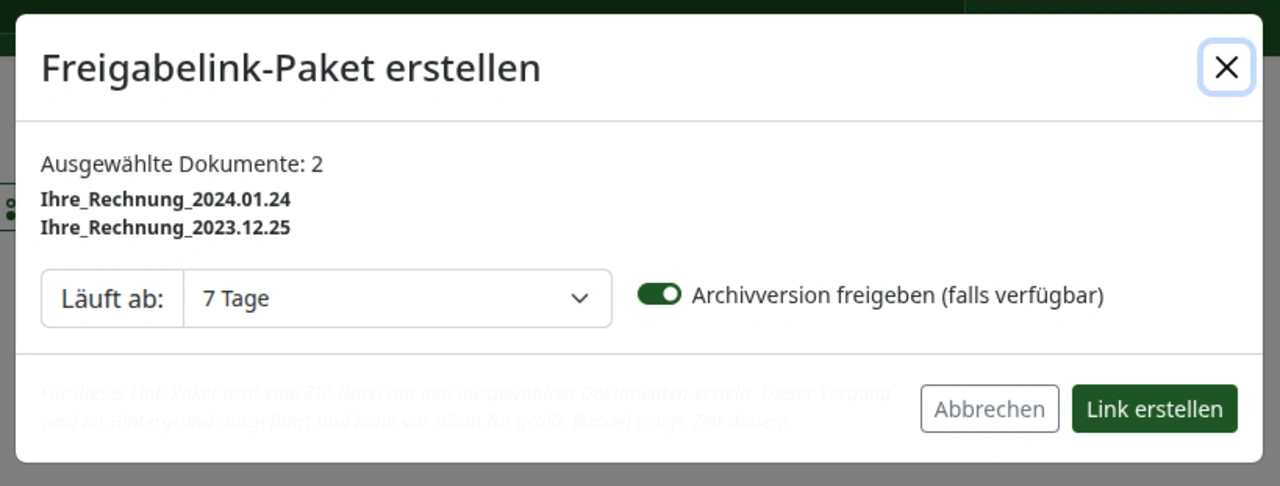
Sharelink Bundles: mehrere Dokumente, ein Link
Sharelinks gab es bisher nur pro Dokument – wer einen Steuerberater mit zehn Belegen versorgen wollte, brauchte zehn Links. Mit 3.0 lässt sich eine Auswahl per Senden → Freigabelink-Paket erstellen zu einem Bundle zusammenfassen; der Empfänger bekommt einen einzigen Link auf ein ZIP-Paket. Bundles werden zudem im Export/Import berücksichtigt.
Arbeitsabläufe werden flexibler
Die Engine für Arbeitsabläufe hat praktische Erweiterungen bekommen:
- „Hat beliebige dieser ...“-Filter: Trigger lassen sich mit ODER-Bedingungen verknüpfen – statt dass alle greifen müssen, reicht eine.
- „In den Papierkorb verschieben“-Aktion: Dokumente lassen sich per Arbeitsablauf in den Papierkorb verschieben.
- PDF-Passwort entfernen: Eine neue Aktion entfernt das Passwort geschützter PDFs beim Consume automatisch (passend hinterlegtes Passwort vorausgesetzt).
- Tag-Barcodes für Splits: Mehrseitige Scans lassen sich anhand spezieller Trenn-Barcodes automatisch aufteilen. Welche Scanner gut funktionieren, zeigt unser Blogartikel zum richtigen Scanner für Paperless-ngx.
Auth, SSO und Plugin-Framework
Bei der Anbindung an eine Identity-Plattform bringt 3.0 einen konfigurierbaren Groups Claim für SSO (PR #11841), App-OIDC-Support für Mobile-Apps (PR #11756) sowie einheitlich SHA256-Checksummen (PR #12432). Neue Permissions wie view_global_statistics erlauben Monitoring-Accounts ohne Admin-Rechte.
Strategisch wichtig ist das neue Plugin-Framework für Document-Parser (PR #12294): Parser lassen sich künftig über Python-Entrypoints (paperless_ngx.parsers) als externe Pakete bereitstellen, statt sie in den Core zu mergen.
Was sich für Self-Hoster konkret ändert
Beim Upgrade solltest du ein paar Breaking Changes kennen:
| Bereich | Vorher (2.x) | Ab 3.0 |
|---|---|---|
| Python | 3.10 noch unterstützt | mindestens 3.11 |
| API | v1 noch erreichbar | nur noch ≥ v9 |
| OCR | OCR_MODE=skip, skip_noarchive |
PAPERLESS_OCR_MODE (auto/force/redo/off) plus PAPERLESS_ARCHIVE_FILE_GENERATION (auto/always/never) |
| Consumer | CONSUMER_POLLING, CONSUMER_POLLING_DELAY, CONSUMER_POLLING_RETRY_COUNT, CONSUMER_INOTIFY_DELAY |
konsolidiert zu CONSUMER_POLLING_INTERVAL und CONSUMER_STABILITY_DELAY, neu: CONSUMER_IGNORE_DIRS |
| Pre/Post-Consume-Scripts | Positionsargumente | nur noch Umgebungsvariablen |
| Barcode-Reader | pyzbar als Option |
entfernt – zxing-cpp bleibt |
| Encryption | Document- und Thumbnail-Encryption | entfernt |
Praxis-Tipp: Beim ersten Start warnt Paperless-ngx vor noch gesetzten alten Variablen – wer eine .env-Datei pflegt, geht sie vorher einmal durch.
Solltest du jetzt updaten?
Mit dem Stable-Release ist die Frage weniger ob, sondern wann. Bei einem privaten Setup ohne Compliance-Druck spricht wenig gegen ein zeitnahes Upgrade – Backup vorausgesetzt. Tantivy und die Erweiterungen der Arbeitsabläufe machen sich im Alltag sofort bemerkbar. Bei Buchhaltung, GoBD-relevantem Archiv oder Vereinsdaten darfst du gelassener sein: Die 2.20.x-Reihe läuft weiter, und wer auf Nummer sicher gehen will, wartet die ersten Patch-Releases der 3.0.x-Reihe ab, bevor der Hauptserver drankommt. Und wenn du Custom-Code (Pre/Post-Scripts, eigene Parser) betreibst, gehören die Breaking Changes vor dem Upgrade auf die Leseliste.
Übrigens: Wer den Aufwand für Major-Upgrades nicht selbst stemmen will, kann Paperless-ngx auch als Managed Service betreiben lassen – Updates inklusive Breaking-Change-Tests übernehmen dann andere.
Häufige Fragen zu Paperless-ngx 3.0
Kann ich direkt von 2.20.x auf 3.0 upgraden?
Ja, das ist der vorgesehene Weg. Wichtig ist die Reihenfolge: erst ein vollständiges Backup (Datenbank, media/, data/), dann die eigene Konfiguration gegen die Breaking-Changes-Tabelle oben abgleichen, dann updaten. Docker-Setups bauen den Suchindex beim ersten Start automatisch neu auf.
Hier erklären wir Schritt für Schritt, wie du updaten kannst.
Was passiert mit meinen verschlüsselten Dokumenten? Die Document- und Thumbnail-Encryption wurde entfernt. Wer das genutzt hat, sollte vor dem Upgrade entschlüsseln. Verschlüsselung auf Storage-Ebene (LUKS) bleibt unberührt – sie war ohnehin der empfohlene Weg.
Schickt Paperless-ngx meine Dokumente jetzt an eine KI? Nur, wenn du es ausdrücklich einschaltest – Paperless AI ist standardmäßig aus. Aktivierst du es, entscheidet das Backend, wohin die Daten gehen: Bei lokalem Ollama bleibt alles auf deinem Server, bei der OpenAI-API gehen die Inhalte an OpenAI.
Fazit
Paperless-ngx 3.0 ist der Schritt, den das Projekt seit der 2.0 vorbereitet hat: eine schnellere Suche, ein sauber dokumentiertes Plugin-System, ein flexibleres Modell für Arbeitsabläufe – und ein paar konsequente Aufräumarbeiten unter der Haube. Für viele Self-Hoster ist Tantivy alleine schon Grund genug für das Upgrade.
Gleichzeitig sind Major-Upgrades nicht kostenlos: Breaking Changes bei OCR-Settings, Consumer-Variablen und der API bedeuten, dass du dir für das Upgrade ein bisschen Zeit nehmen solltest. Wer das nicht selbst machen will, hat mit Managed-Hosting eine valide Alternative.